
In my last post I talked about the REST service calls of what I said at the time was possibly the ugliest SPA of all time. I wanted to do it with no dependencies, which means interacting with XMLHttpRequest directly, and that isn’t anybody’s idea of pretty. No dependencies also means no promises, and once you’ve programmed with promises for a while, working without them on networking code feels like a step backwards. In this post I’m going to rewrite the ugly SPA with the following changes:
- I’m going to use fetch for all REST calls. fetch is the future, or so they tell me. And it gives me a comfortable promises-based API.
- I’m also going to use “odata=nometadata” for all of my REST calls. As I mentioned in my last post, this may not work in a SharePoint 2013 environment unless Service Pack 1 has been installed and changes have been made to the SharePoint web.config to support JSON light. So if you’re on 2013 and it doesn’t support JSON light, you need to use “odata=verbose” as shown in my previous post.
As I work through the code, I’ll point out differences between “odata=nometadata” and “odata=verbose”. There really aren’t that many differences.
What We’re Going to Build
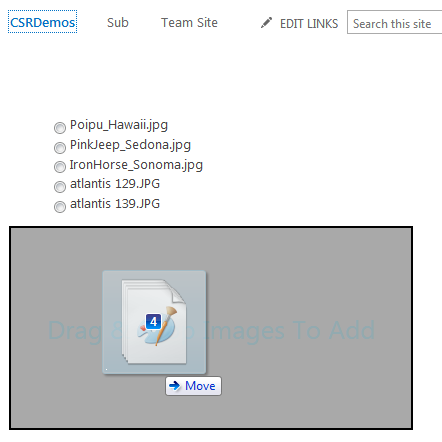
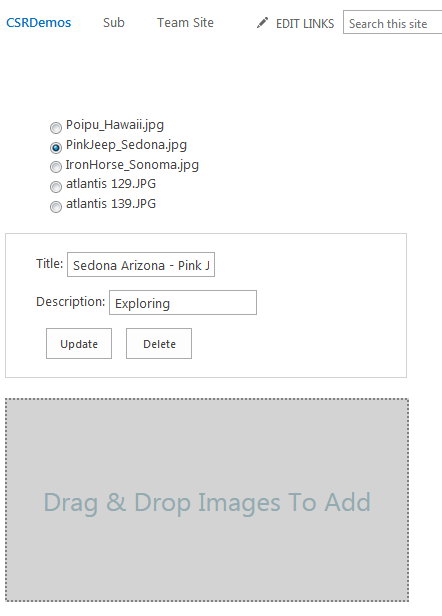
The HTML
There is nothing special about the HTML, but since I’m going to be manipulating it as I demonstrate the CRUD operations, I’ll show it here so you can refer back to it. It consists of an un-ordered list to show pictures currently in the library, a small form for edit/delete, and a div with some structure to implement drag and drop files.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | <!--List of pictures (name and radio button)--> <ul id="picturelist" style="list-style: none"> </ul> <!--Update Form--> <div id="updatePanel" class="updatepanel"> Title: <input type='text' id='title' val='' /> Description: <input type='text' id='description' val='' /> <button type='button' id='Update'> Update </button> <button type='button' id='Delete'> Delete </button> </p> <!--Drag and Drop div--> <div id="dragandrophandler"> <div id="draganddropbusy" style="display:none"> <!--Change this path for your environment--> <img src="/_layouts/images/progress.gif"> </p> <div id="draganddroplabel">Drag & Drop Images To Add</p> </p> |
As I process the read operation and shove list items into the un-ordered list, I’ll also add some hidden data- attributes to the item to store things like the title, description, id, and etag, that will be needed for other CRUD operations later on, so a list item will end up looking like this:
1 2 3 | <li data-id="333" data-title="Poipu - Hawaii" data-description="Snorkeling" data-etag="4"> <input name="item" id="item333" value="333" type="radio">Poipu_Hawaii.jpg </li> |
Browser Support
Before we dive into the code, we have to look at how well supported fetch is in browsers. It’s still pretty new as far as browser standards go and browsers have not historically been that quick to implement new standards. You can dig into the gory details on Can I Use Fetch, but to summarize, no version of Internet Explorer supports fetch. Also, fetch is a promises-based API, and no version of Internet Explorer supports the promises API (Can I Use Promises).
Now it’s becoming fashionable to say we’re just not going to support Internet Explorer because of these kinds of shortcomings, but it is not reasonable in a SharePoint application to not support the browsers that Microsoft supports. And often, at this point in the discovery process of browser support for feature X, I conclude that feature X isn’t ready for prime-time and we shouldn’t use it yet. But fetch is the future, it is now supported to some degree by all evergreen browsers, and there are good polyfills available to use it in unsupported browsers, without adding a ton of overhead. And anyway, what the heck, it’s my blog post and I want to play with fetch.
So to get fetch support in most browsers, I include polyfills for Promise and fetch loaded from a CDN like so:
1 2 3 4 5 | <script type="text/javascript"> window.Promise || document.write('<script src="https://cdn.jsdelivr.net/npm/es6-promise@4/dist/es6-promise.auto.js"><\/script>'); </script> <script src="https://cdn.jsdelivr.net/npm/whatwg-fetch@2.0.4/fetch.js"></script> |
It doesn’t take a rocket scientist to notice that I’ve brought in two different polyfills here in two very different ways, so what gives? Let me ‘splain:
- I bring in fetch as a straight-up polyfill so it will define window.fetch if it’s not already defined, and replace it if it is already defined. I do this because it didn’t take long while converting this SPA to fetch, for me to run into problems with the native implementation of fetch on some browsers. So even if the browser implements fetch, it doesn’t mean it implements it well by the standard, or completely. Anyway, the point is, I couldn’t get through basic CRUD without using the polyfill, and I’ll explain where the native implementation of fetch tripped me up when I get to it (hint, it’s in Create).
- On the other hand, I chose to use the browser’s native Promise implementation if it has one. Promises are pretty straightforward, and fetch doesn’t do anything crazy with them, so I haven’t seen any issues with the browser implementations of promises that required me to replace the native implementation with a polyfill to do basic CRUD operations.
Fetch 101
There are plenty of good “Intro to fetch” blog posts out there, and I’ll include at least one in the reference section below, so I’m not going to get very deep in my discussion of the fetch API. But I do need to talk about it a little so I can explain why I made specific choices later on, so here goes.
Below is a call to the lists service to get the schema of a list. I made this call in my last post to get the ListEntityTypeFullName, so I could construct the metadata for the changes structure I pass back to SharePoint during the update operation. I won’t actually need that in this post, because I’m switching from “odata=verbose” to “odata=nometadata”, so I don’t need to include metadata in my changes object for updates. Just the same, it’s a pretty simple call for demo purposes, so I’ll use it here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | var url = _spPageContextInfo.webAbsoluteUrl + "/_api/Web/Lists/GetByTitle('" + listTitle + "')"; // call the REST service and get the list schema fetch(url, { credentials: "include", headers: new Headers({ 'accept': 'application/json;odata=nometadata' }) }).then(function(response) { if (response.stataus < 200 || response.status > 400) { throw new Error(response.status + " " + response.statusText); } return response.json(); }).then(function(json) { alert(JSON.stringify(json, null, 4)); }).catch(function(response) { alert(JSON.stringify(response, null, 4)); }); |
When I make this call, assuming listTitle is a valid title for a list in my SharePoint site, I get a popup dialog like the one shown below. Obviously, there is a great deal of information coming back. In my last post I added ?$select=ListEntityTypeFullName to the URL, which made the response much smaller. By not specifing any select, I get back the “whole” schema, like so:

Now going back to the code, I’d like to point out some things that I don’t necessarily love about the fetch API:
- Fetch returns a promise, which resolves to a response. The response contains information about both the HTTP request and the HTTP response. To actually get the payload of the response, I have to call either response.json() or response.text(), both of which return another promise.
- This means that in order to get to what I’m asking for, I have to daisy chain at least two then handlers. If I have a lot of REST calls in my code, that can get annoyingly repetitive.
- Also, I need to explicitly tell fetch that I want it to include the user’s credentials in the request. The default is not to include them, and fetch doesn’t let me change the defaults. When doing SharePoint REST calls, you can probably pretty well count on always needing to include credentials. Again, annoyingly repetitive.
- And last, but certainly not least, notice that I’ve got code in the first then handler to check if the response status is outside of the range of success according to HTTP status codes. Fetch doesn’t consider it to be an error and send it to the catch handler unless it’s a real network error, like a failed DNS lookup or failure to connect. A “404 Not Found” status is a perfectly fine HTTP response, so fetch sends it to the then handler. The result is that I have to handle what I consider to be errors in two different places, which obviously isn’t ideal. And again, annoyingly repetitive.
Annoyingly repetitive code is synonymous with “you’re going to be doing a lot of cutting and pasting,” which isn’t going to win you any prizes for coding best practices.
All of this is to say that fetch is a pretty low level API. It doesn’t deal with HTTP error codes, because HTTP is way up at the application layer, and fetch is more down at the network layer. I’ve read about these “deficiencies” in a number of blog posts like Why I won’t be using Fetch API in my apps. I don’t disagree with anything said in that post about fetch shortcomings, in fact I pretty much just made most of the same points, but the title and the conclusion are a bit melodramatic for me.
And I’ve heard others say, if you’re going to wrap fetch, you may as well use a third-part API like axios. But ultimately, I decided to wrap fetch, and in about 35 lines of code I ended up with something that addressed all of these issues to my satisfaction. Axios may be pretty light-weight, but it’s more than 35 lines of code.
A Simple Fetch Wrapper
Below is my fetch wrapper. It’s just a function, called fetchx, that takes the same parameters as fetch (sort of), calls fetch, and returns a promise. It does the following:
- First, it tells fetch to always include credentials.
- Then, if the init.headers is not of type Headers, it converts it to type Headers, so I can now pass in headers as an arbitrary object used as a map, just like $.ajax or axios.
- Then it calls fetch.
- It implements a then handler, which does a number of things:
- First it checks the HTTP response status and throws an exception on return codes that are obvious errors, which passes off handling to the next catch handler.
- Then, if there is no payload, it just returns the response, passing processing off to the next then handler.
- Next, if the expected response is “application/json”, it returns the promise from calling response.json(), passing processing to the next then handler. If it expected a JSON response but it doesn’t look like the response is JSON, it throws an exception passing off handling to the next catch handler.
- Finally, if it has a payload but doesn’t expect JSON, it returns the promise from response.text(), passing off processing to the next then handler.
Basically, all of the things I identified as annoyingly repetitive are taken care of, one time and in one place in the code. Look Ma’, no cut an paste.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | function fetchx(url, init) { init = init || {}; // all SharePoint operations are going to need this, so let's default. init.credentials = "include"; // turn objects into Headers, also see if we're expecting a json response if (init.headers && !(init.headers instanceof Headers)) { init.headers = new Headers(init.headers); } /* Call fetch, process obvious error responses, pre-process json responses, and return the promise for further processing. */ return fetch(url, init).then(function(response) { // non-success response if (response.stataus < 200 || response.status > 400) { throw response; } // no content by design if (response.status === 204) { return response; } // no content, but not not by design? if (response.headers.get("content-length") === "0") { return response; } // process json responses if (init.headers) { var accept = init.headers.get("accept"); if (accept && accept.indexOf("application/json") > -1) { var contentType = response.headers.get("content-type"); if (contentType && contentType.indexOf("application/json") > -1) { return response.json(); } else { throw new TypeError("Oops, should have gotten JSON, but didn't!"); } } } // no errors and some kind of payload, but also not json return response.text(); }); } |
Note I could have add a lot more to the wrapper, removing some of the annoying redundancy from the SharePoint REST API. For instance, how about:
1 2 3 4 5 | if (init.method === "DELETE") { if (!headers.has("X-HTTP-Method")) { init.headers.append("X-HTTP-Method", "DELETE"); } } |
How often, do you imagine, am I going to use the HTTP verb DELETE, but not want the ‘X-HTTP-Method’ also set to DELETE? I can think of at least 25 more lines of SharePoint/REST specific defaults I could add to greatly streamline my usage. I’m not actually going to do any of that in this post, because it would hide the details and make this a pretty poor tutorial.
Create with Fetch
So below is my create call using fetch, and I really don’t have a lot to say about it. The fetch stuff was explained above and the SharePoint REST specific stuff I explained in my last post.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | var updating = 0; // construct a url to upload a file var url = _spPageContextInfo.webAbsoluteUrl + "/_api/web/lists/getByTitle('" + listTitle + "')" + "/RootFolder/Files/add(url='" + file.name + "',overwrite='true')?" + "@TargetLibrary='" + listTitle + "'&@TargetFileName='" + file.name + "'"; // update the form digest if necessary UpdateFormDigest(_spPageContextInfo.webServerRelativeUrl, _spFormDigestRefreshInterval); // upload the file with fetch fetchx(url, { method: "POST", headers: { "accept": "application/json;odata=nometadata", "X-RequestDigest": document.getElementById("__REQUESTDIGEST").value }, body: buffer }).then(function(json) { updating--; }).catch(function(error) { updating--; alertError(error); }); |
On the other hand, if you’re still with me you may recall that I said earlier that Create was where I ran into problems with at least one browser’s native fetch implementation. When I first started this I had intended to use the native implementation if there was one, but on the latest version of Chrome, this code throws an exception.
Stepping through it in the debugger, I ended up in a big switch/case statement based on the content-type header. Basically, what it said is if the content-type is set to “application/json” go ahead an process it. If it’s anything else, throw a “Not supported” exception. There certainly isn’t anything in the fetch specification that says the content-type must be “application/json”. And we’re uploading an image, it’s a binary payload. There might be some way to format this as JSON that SharePoint would be able to work with, but at a bare minimum it would require something like base64 encoding the binary data, which will bloat the payload and isn’t a very good idea.
Anyway, the result from my point of view is that if I’m going to use fetch, I’m going to polyfill it for now. And until the native implementations of at least all evergreen browsers are more correct and complete, I’ll continue to polyfill it.
Read with Fetch
Read is where you might expect to yield the biggest gains by specifying “odata=nometadata”, since otherwise it would tack on metadata to each item and it could be returning a lot of items. Depending upon your needs, you should prepare to be disappointed. If I call Lists/Items with the request parameters set to ‘$select=FileRef,Title,Description,Id,Created,Modified,GUI’, as I did in my last post, each item comes back looking something like this in the debugger:

Ask and ye’ shall receive. But wait! There’s something missing here. Where’s the eTag. In my last post I showed how the eTag comes back as part of of the __metadata. But since we’ve specified “odata=nometadata”, another way of putting that is you get what you ask for. There is another way of getting it though. In a document library, an SPListItem has a File property. To get the lists service to return that file property I have to tell it to expand the file property, by adding &expand=File to the request parameters. When I do that, the items look like this in the debugger:
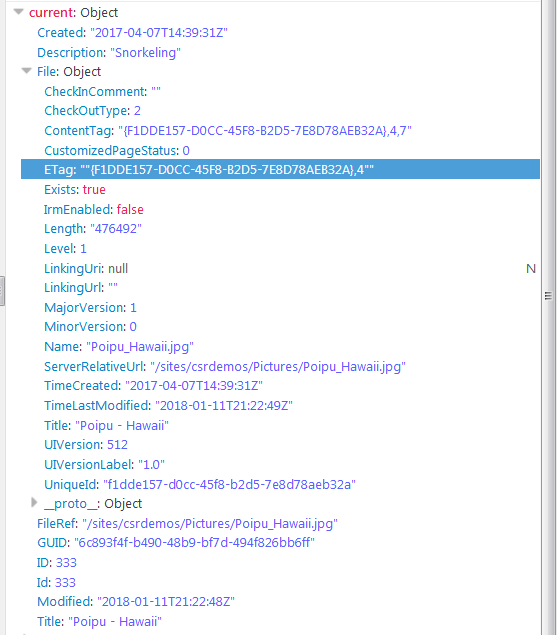
So now we have a file, and the file has an ETag property. It’s not exactly the same as what we got before. It’s a guid, followed by a comma, followed by a number. That number is the eTag that was in the __metadata before.
Now the eTag is only required during update operations, and only if you want to prevent a user from updating something that has already been updated by someone else. If you’re perfectly happy with “last one in wins,” then you can put “*” in the IF-MATCH header (where the eTag goes) on update operations and they will work regardless of version. That’s what I’ve done in my update operation below, but I left the expand file code and the eTag parsing in my Read call just so you can step through it and see an example of expand.
I should point out one other thing. We switched to “odata=nometadata” in an effort to reduce the payload. But expanding the file, as I’ve done, increases the payload by a lot more than specifying “odata=verbose”. There is a way around this. In addition to adding &expand=File, if I add ,File/ETag to the &select, I’ll get back the File with only one property, the ETag. Still, this gets back the eTag for a document. I don’t know how you get it back for a list item without specifying “odata=verbose”. And getting the File.ETag and parsing it is a bit ugly anyway. If I decide I need eTags, I’m probably just going to specify “odata=verbose” for the read operation.
In the code below, I’ve highlighted everything that changed since my last post. That’s mostly the code that parses out the eTag, but there are two other lines that are highlighted. That’s because by switching from “odata=verbose” to “odata=nometadata”, the results come back as an array in json.value instead of in responseJSON.d.results. Other than that, the code is remarkably the same.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | var pictureList = document.getElementById("picturelist"); var serviceUrl = "/_api/Web/Lists/getByTitle('" + listTitle + "')/Items"; var serviceParams = "$select=FileRef,Title,Description,Id,Created,Modified,GUID&$expand=File"; var url = _spPageContextInfo.webAbsoluteUrl + serviceUrl + "?" + serviceParams; fetchx(url, { method: "GET", url: url, headers: new Headers({ 'accept': 'application/json;odata=nometadata' }) }).then(function(json) { for (var i = 0; i < json.value.length; i++) { var current = json.value[i]; current.Name = current.FileRef; current.Name = current.Name.substr(current.Name.lastIndexOf("/") + 1); current.Title = current.Title || ""; current.Description = current.Description || ""; if (current.File && current.File.ETag) { var tmp = current.File.ETag; if (tmp.indexOf(",") > 0) { current.eTag = tmp.substr(tmp.indexOf(",") + 1); } } var input = document.getElementById("item" + current.ID); if (input) { var li = input.parentNode; li.setAttribute("data-title", current.Title); li.setAttribute("data-description", current.Description); if (current.eTag) li.setAttribute("data-etag", current.etag); } else { var container = document.createElement("div"); container.innerHTML = "<li data-id='" + current.ID + "' " + "data-title='" + current.Title + "' " + "data-description='" + current.Description + "' " + (current.eTag ? "data-etag=''" + current.eTag + "''" : "") + ">" + "<input type='radio' name='item' id='item" + current.ID + "' value='" + current.ID + "' />" + current.Name + "</li>"; pictureList.appendChild(container.children[0]); } } if (index) { var current = document.getElementById("item" + index); current.checked = true; var title = current.parentNode.getAttribute("data-title"); var description = current.parentNode.getAttribute("data-description"); document.getElementById("title").value = title; document.getElementById("description").value = description; document.getElementById("updatePanel").style.display = "block"; } else { document.getElementById("updatePanel").style.display = "none"; document.getElementById("title").value = ""; document.getElementById("description").value = ""; } }).catch(function(error) { alertError(error); }); |
Update with Fetch
There isn’t much to say about the update operation. Other than the syntactic differences between the ajax wrapper in my last post and the fetchx wrapper in this one, the only difference is that I specify “*” as the eTag as previously mentioned, so the update will succeed regardless of version.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | // construct the merge object with a property for each field we want to update, but no meta data var changes = { 'Title': document.getElementById("title").value, 'Description': document.getElementById("description").value }; changes = JSON.stringify(changes); // construct the REST service url var serviceUrl = "/_api/Web/Lists/getByTitle('" + listTitle + "')/Items(" + id + ")"; var url = _spPageContextInfo.webAbsoluteUrl + serviceUrl; // call the REST service as a MERGE fetchx(url, { method: "MERGE", headers: { 'accept': 'application/json;odata=nometadata', 'content-Type': 'application/json;odata=nometadata', 'X-RequestDigest': document.getElementById("__REQUESTDIGEST").value, 'X-HTTP-Method': 'MERGE', 'IF-MATCH': '*' // set etag to any, as overwrite always }, body: changes }).then(function() { // on success, reload the images list and pop up an alert readImages(); alert("Successfully updated the item!"); }).catch(function(error) { alertError(error); }); |
Delete with Fetch
And finally, below is delete. Other than the syntactic differences between the ajax wrapper and the fetchx wrapper, nothing has changed here.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | // get the picture name var name = document.querySelector("li[data-id='" + id + "']").textContent; // construct the url for the REST service var base = (_spPageContextInfo.webServerRelativeUrl === "/" ? "" : _spPageContextInfo.webServerRelativeUrl); var serviceUrl = "/_api/web/getfilebyserverrelativeurl('" + base + "/" + listTitle + "/" + name + "')"; var url = _spPageContextInfo.webAbsoluteUrl + serviceUrl; // call the rest service fetchx(url, { method: "DELETE", headers: { 'accept': 'application/json;odata=nometadata', 'X-RequestDigest': document.getElementById("__REQUESTDIGEST").value, 'X-HTTP-Method': 'DELETE' }, }).then(function(json) { // delete the LI element for the now deleted picture var current = document.getElementById("item" + id); current.parentNode.parentNode.removeChild(current.parentNode); // hide the update panel, since nothing is selected now document.getElementById("updatePanel").style.display = "none"; // reload the UL of images readImages(); }).catch(function(error) { alertError(error); }); |
Sum Up
The end result is that I think I like fetch. On projects where jQuery is already heavily in use, I’m perfectly happy to continue using $.ajax, but if I just want a better Ajax experience than XMLHttpRequest (and who wouldn’t), I’ll probably polyfill fetch for now. And as I continue to blog about SharePoint and REST, it will probably be using fetch.
References
- fetch API – David Walsh
- Why I won’t be using Fetch API in my apps – Shahar Talmi
- Making Your REST Calls Simpler by Changing the Metadata Setting – Marc Anderson
- SharePoint 2013: How to refresh the Request Digest value in JavaScript – Wictor Wilén